




算力芯片,如何突围?
编者按:关于后进赶超先进,网上有太多的文章和视频。作为常年从事计算机算力芯片相关工作的我,今天就从算力芯片这个视角出发,谈谈对国内算力芯片如何实现突围的个人的一些看法。
1 成熟赛道,后进赶超先进,很难
1.1 CPU的江湖恩仇
上世纪70年代,Intel发明了CPU。通过对CPU的持续投入,Intel逐渐获得了市场的优势,并逐渐构建起了自己的x86生态,这包括外围的硬件合作伙伴、BIOS等固件开发、操作系统软件、工具链以及应用软件生态等等。
RISC是一个失败的例子。X86是CISC架构,随着CISC指令的复杂度越来越高,越来越难以控制,RISC架构逐渐兴起。RISC架构处理器提倡简化指令集设计、固定指令长度、统一指令编码格式、加速常用指令。RISC架构成为很多处理器的首选,并且也成为了许多计算机教材的经典CPU设计案例。但即便如此,在市场竞争上,RISC架构仍然输给了CISC。
安腾是Intel自己的一个失败的例子。安腾是Intel于2001年推出的64位架构的CPU处理器。虽然是Intel的亲儿子,虽然是功能强大的64位CPU架构,虽然安腾的架构和微架构设计非常优秀,但因为安腾和x86的不兼容,完全一个新的生态,也不可避免的走向了失败。最后成就了AMD64的成功。
ARM的成功,更多源于商业模式。最开始,ARM自研的处理器性能都非常差,其自研的处理器性能通常是低于一些巨头客户自研的ARM架构CPU。但因为ARM是一个中立的CPU架构和IP供应商,很多巨头愿意扶持着它向前迈进。最后在智能手机时代,ARM大获成功。有了资金实力之后,ARM后续CPU的性能才逐渐赶上并且部分超越了自己的巨头客户。
RISC-v,后起之秀,明日之星,未来可能的成功也是依赖于更优的商业模式。跟ARM当年的处境类似,目前的RISCv性能和生态都要弱于x86和ARM,但因为更优的商业模式(完全开源开放的,并且得到广泛共识的免费的处理器),其发展也是相当迅猛。
1.2 NVIDIA,从十年磨一剑到市值万亿
传统的GPU是图形加速卡,本质上是众多各种领域各种场景加速卡中的一员。除了GPU之外,其他众多的各类加速卡,几乎没有成功的案例。GPU之所以最终成功,来自于00年代NVIDIA的转型:一方面,是GPU从传统的图像加速卡,改造成面向并行计算的GPGPU;此外,为了降低开发的门槛,把更多的资源投向了CUDA,并且对外宣称自己是一家软件公司。
即便策略正确,最终的成功验证也差不多是十年之后。CUDA的最早期版本是在2005年前后发布的,直到2012年深度学习的崛起,GPU才开始真正脱颖而出,也直到2018年大模型兴起,以及2013年ChatGPT的火爆,才把NVIDIA推上了最高的神坛。
1.3 简单总结
经常有企业喊出口号是“要做中国的xxx”,但“学我者生,像我者死”,芯片是一个国际化的市场,全球竞争,这样亦步亦趋的学习巨头企业的做法,无异于“邯郸学步”。
展开全文
在成熟的赛道,后进如果靠模仿先进前进,那必然无法成功。后进需要有差异化,有创新,有优势,才有可能成功。并且,后进要想成功,其难度远高于先进者当年的难度。
2 技术的变革,是后进赶超先进的关键时机
国产新能源汽车,是后进赶超先进的经典案例。据中国汽车工业协会整理的海关总署数据显示,2023年上半年,汽车整车出口234.1万辆,同比增长76.9%;1~7月,汽车出口总值3837.3亿元,增长118.5%。中国汽车出口首次超过日本,跃居世界首位。新能源汽车是中国汽车出口的核心增长点。2023年1~6月出口新能源车80万辆,同比增长105%。
在成熟赛道,先进具有技术优势、市场优势、专利优势、品牌优势等等,后进赶超先进很难。但如果是技术的变革期,后进就可以在新的技术领域提前布局,让双方站在同一个起跑线,以此来获得“公平”竞技的机会,从而有可能实现超越。国产汽车,就是抓住了新能源和智能汽车这一波浪潮,迅速地达到了汽车出口量全球第一。
那么,芯片的变革机会在哪里?
3 AGI大模型的挑战
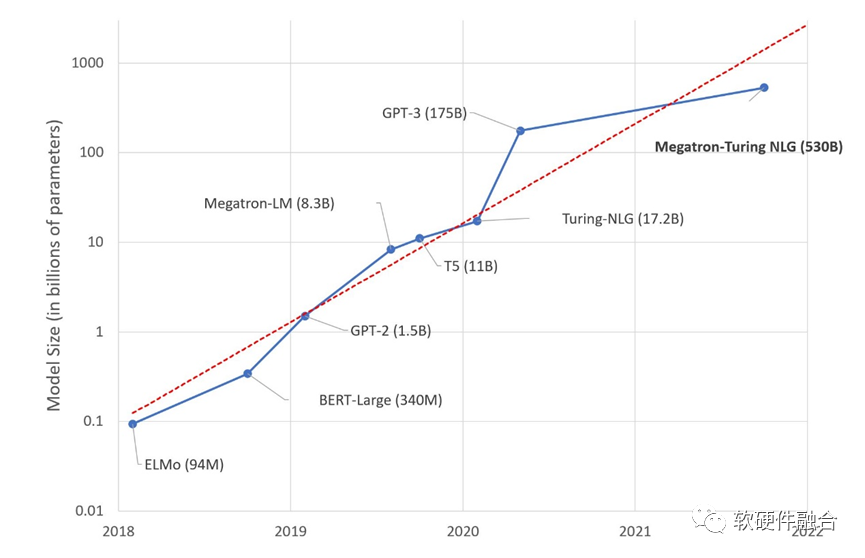
2023年初的AI大模型,“不约而同”的参数规模停留在千亿级,为什么?
核心的原因在于,这是目前的GPU计算集群所能支撑的算力上限:
一方面,单芯片算力已经瓶颈,算力增长极度缓慢。
另一方面,受限于目前的服务器以CPU为中心的架构约束,以及网络的交互效率所限,集群规模也已经达到了上限。
还有一个很重要的原因,就是算力的建设和运营成本,也已经达到了一个天文数字。
一方面,单芯片算力已经瓶颈,算力增长极度缓慢。
另一方面,受限于目前的服务器以CPU为中心的架构约束,以及网络的交互效率所限,集群规模也已经达到了上限。
还有一个很重要的原因,就是算力的建设和运营成本,也已经达到了一个天文数字。
目前CPU性能早已瓶颈,GPU性能即将见顶并且成本高昂,而AI芯片太过于专用,不适用于快速变化的模型算法/算子和业务逻辑。
如何解决?我们也可以给一个简单的答案:
一方面,持续不断的Scale up,通过更多的处理器内聚,数量级的提升单芯片的性能;
另一方面,持续不断地增强芯片的内部交互(打破已有的以CPU为中心的架构)和外部交互(增强高性能网络)。数量级的提升集群中服务器的数量。
此外,大芯片需要通用。能否实现足够的通用性,是大芯片能够大规模落地的最重要因素。
还有一个很重要的,要通过一些机制,数量级的降低算力的成本。
一方面,持续不断的Scale up,通过更多的处理器内聚,数量级的提升单芯片的性能;
另一方面,持续不断地增强芯片的内部交互(打破已有的以CPU为中心的架构)和外部交互(增强高性能网络)。数量级的提升集群中服务器的数量。
此外,大芯片需要通用。能否实现足够的通用性,是大芯片能够大规模落地的最重要因素。
还有一个很重要的,要通过一些机制,数量级的降低算力的成本。
4 芯片工艺的快速进步
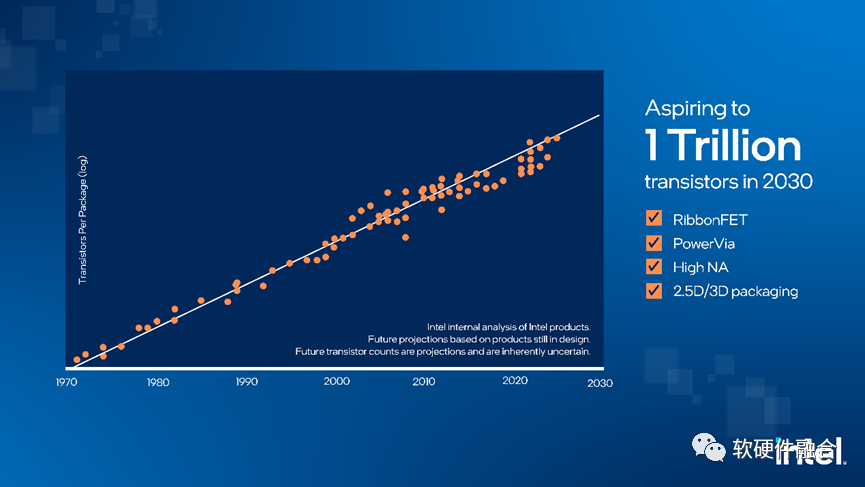
工艺持续进步,Chiplet先进封装也越来越成熟。从2D的工艺到3D的封装再到Chiplet的4D封装,芯片的底层实现技术仍在快速发展。
目前的大算力芯片,通常在500亿晶体管左右。Intel的规划是在2030年,达到1万亿晶体管。这意味着,相比目前的芯片,计算规模再提升20倍。
如此大规模的晶体管资源,我们该如何更好地利用?
5 算力芯片变革的历史机遇
5.1 系统架构创新
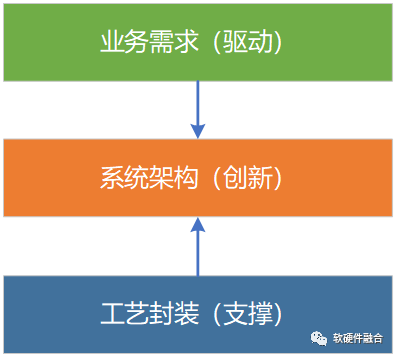
一方面是需求牵引,一方面是工艺支撑,两方面的因素,都需要我们在系统架构层次,做更多的创新。
从单核到多核、从同构到异构,从单异构到多异构,再从多异构到异构融合,是一个计算架构从简单到复杂的继承并发展的过程。

芯片设计规模越来越大,单芯片集成更多架构的处理器成为一种非常常见的设计。这种多异构混合计算架构,Intel称为超异构计算。在2023年9月份发布的《异构融合计算技术白皮书》中,采用了更严谨更准确的一种叫法,“异构融合计算”。深刻揭示了多异构混合计算的关键,在于异构处理器之间的协同和融合。
5.2 大芯片如何能够通用?
系统规模越来越大,变化越来越快,从而使得在大算力芯片,通用性比性能更重要。而定制的加速算力芯片覆盖场景少,生命周期短,难以大规模落地。
此外,相比专用,通用是更高级的能力。通用计算,需要从众多需求中提炼和拆解出通用的部分和组件,通过软件编程,灵活地组合出用户所需的形形色色的功能。并且还要实现性能和灵活性的兼顾。
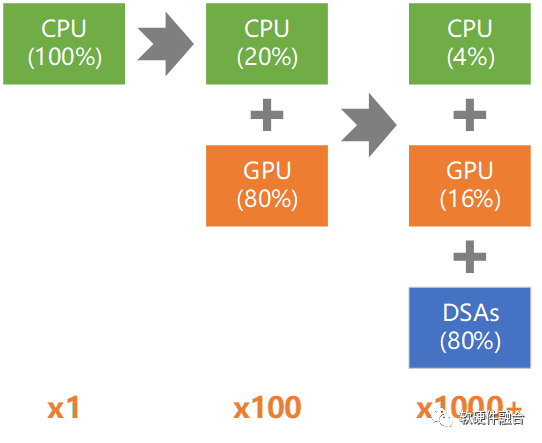
那么,如何实现通用?能够通用的本质原因是什么?
系统规模越大,“二八定律”特征越明显。这样,我们可以把确定性的共性的部分硬件加速实现,相对不确定的个性的部分通过软件编程实现。

在六代计算架构的基础上,增加“通用”约束,变成三代通用计算架构:
第一代单核和第二代多核合并成CPU同构。
取消专用的DSA异构计算阶段,异构计算仅保留GPU的通用异构。
多异构要想成功,就需要融合;异构融合要想成功,就需要通用。因此,从终局思维思考,最终可落地的方案,会是通用的异构融合计算。
第一代单核和第二代多核合并成CPU同构。
取消专用的DSA异构计算阶段,异构计算仅保留GPU的通用异构。
多异构要想成功,就需要融合;异构融合要想成功,就需要通用。因此,从终局思维思考,最终可落地的方案,会是通用的异构融合计算。
5.3 从单兵作战到团队协作
受限于先进工艺,我们无法实现最强算力的芯片。但我们可以通过更多资源的协作,来实现更强的群体智能:
方法一,异构融合。通过异构融合的计算架构创新,实现更多处理器核心的协同和融合。可以在工艺落后1-2代的情况下,实现单个芯片的算力更优。
方法二,算力网络。通过算力网络、东数西算,实现跨集群的算力调度和算力协同,可以实现算力资源的高效利用。
方法三,智能网联。通过终端的智能网联,实现云端协同。清华的李克强院士提出的智能网联汽车中国方案,强调车(终端)、路(MEC接入)、边、云的深度协同,在单体算力有限的情况下,可以实现更智能化的用户服务体验。
方法四,云网边端融合。更庞大算力节点,更高性能更低延迟的网络,更强大的算力基础设施,实现更强大的宏观数字系统。
方法一,异构融合。通过异构融合的计算架构创新,实现更多处理器核心的协同和融合。可以在工艺落后1-2代的情况下,实现单个芯片的算力更优。
方法二,算力网络。通过算力网络、东数西算,实现跨集群的算力调度和算力协同,可以实现算力资源的高效利用。
方法三,智能网联。通过终端的智能网联,实现云端协同。清华的李克强院士提出的智能网联汽车中国方案,强调车(终端)、路(MEC接入)、边、云的深度协同,在单体算力有限的情况下,可以实现更智能化的用户服务体验。
方法四,云网边端融合。更庞大算力节点,更高性能更低延迟的网络,更强大的算力基础设施,实现更强大的宏观数字系统。
5.4 总结
从异构到异构融合计算,计算架构的变革,给了我们“弯道超车”的时机;历史机遇稍纵即逝,需要快马加鞭,加大投入。
抓住计算架构变革的历史时机,实现算力芯片的弯道超车!








评论