




AI加速引擎 PAI-TorchAcc:整体介绍与性能概述
1. 简介
PAI-TorchAcc(Torch Accelerator)是阿里云人工智能平台PAI开发的Pytorch上的大模型训练加速框架。
PAI-TorchAcc提供了一套基于Pytorch的简洁、易用的接口,无需进行模型转换就可以无缝地接入HuggingFace上的模型,并用多种分布式策略进行训练加速。
PAI-TorchAcc借助社区PyTorch/XLA,通过 LazyTensor 技术将Pytorch代码转换为静态执行图,基于计算图,结合阿里云上的计算资源情况,进行了大量的GPU硬件上模型训练的针对性分布式优化、计算优化。
得益于简单的模型接入方式、基于计算图的优化,PAI-TorchAcc能够灵活地支持各种大模型的多种规模,兼容不同的硬件。PAI-TorchAcc支持常见大模型1B-175B的训练,训练吞吐相对PyTorch原生、Megatron-LM均有提升,如LLaMA系列模型,相比PyTorch原生提升了140%,相比Megatron-LM提升了5%,在A100上MFU达到70%,8卡到128卡线性加速比达到15.6X。
2. 背景和需求
2.1 背景
大模型训练
近年来,大语言模型、视频生成类模型迅速发展,它们基于庞大的文本、图片、视频等数据集进行训练,执行多种自然语言处理、图像生成、视频生成等任务,具备强大的理解和生成能力。随着计算资源和技术的不断进步,大模型的参数量已增长到数亿甚至数万亿级别,例如LLaMA、GPT-3、通义千问、Sora等,这些模型在许多基准测试上表现出了前所未有的性能。
然而,训练大模型需要极高的成本。比如使用Megatron-LM预训练一个OPT-175B模型需要上千张A100训练2个月[1],硬件利用率MFU约47%,期间因为硬件故障经历了几十次checkpoint的加载和续训练。使用PyTorch FSDP进行LLaMA-2-70B的微调也需要16张A100运行约13.5小时[2]。NVIDIA A100、H100等硬件资源价格高昂且不易获取,市面上也逐渐出现了其他性价比更高的硬件资源。
加速不同的大模型的预训练、续训练、微调,充分利用不同的硬件资源,提升资源利用率,是降低大模型训练成本的一个有效途径。
Megatron-LM
NVIDIA Megatron-LM[3]是一个基于 PyTorch 的分布式训练框架,用来训练基于Transformer的大模型。Megatron-LM综合应用了数据并行、模型并行、流水并行来实现GPT-3等特定模型的训练。然而,不同的大模型、训练数据集接入Megatron-LM十分不灵活,需要将checkpoint和数据格式进行转换。同时,Megatron-LM虽然对一些模型算子做了手动的优化,在面对不同模型的不同计算模式时,难以自动地应用这种手动的优化。
DeepSpeed
DeepSpeed[4]是微软开源的一个PyTorch上的大模型分布式训练框架,支持ZeRO和流水并行,并且可以结合Megatron-LM运行3D并行。DeepSpeed已经成为HuggingFace transformers库中一个训练组件。然而DeepSpeed性能表现较差,并且和Megatron-LM同样存在面对不同计算模式时无法灵活优化的限制。
展开全文
PyTorch/XLA
PyTorch/XLA[5]将PyTorch和 OpenXLA相结合,使用LazyTenor技术,将PyTorch代码转换为静态执行图,在静态图上进行计算图优化和后端编译优化。Pytorch/XLA主要是针对TPU 场景进行优化,在GPU上还存在一定问题和优化空间,如不支持Transformers 模型常用的FlashAttention加速算子、不支持 torchrun 拉起、计算通信 Overlap 差、显存开销大等问题。
2.2 需求
基于以上背景,我们需要一个大模型分布式训练引擎,能够方便接入多变的PyTorch模型,尤其是Transformer类模型,兼容多种硬件。在不同模型变化的计算模式下,在不同硬件变化的硬件架构和计算、访存能力下,能够自动地对计算进行优化,尤其在阿里云的硬件上能够表现较高的性能。同时,大模型导致单卡内存和显存无法完全放下,不同的模型需要结合不同的分布式策略,合理通信,完成多卡训练并提升线性加速比。
3. PAI-TorchAcc核心技术特性
灵活的模型接入
支持LLaMA系列、Qwen、BaiChuan、ChatGLM、OLMo、Bloom等常见的大模型1B-175B的训练;
无缝对接HuggingFace中的模型;一键接入和加速Pytorch模型。
千亿级模型参数量
已经支持1B到175B大模型训练;
全面的训练模式
支持混合精度训练,包括Float32、Float16、BFloat16等;支持Pytorch模型的预训练、微调和续训练。
组合的分布式策略
支持Data Parallel、Tensor Parallel、Sequence Parallel、Fully Sharded Data Parallel、Pipeline等分布式策略及其组合。
自动计算优化和显存优化
使用手动的Gradient Checkpoint和自动的Rematerialization降低峰值显存;自动进行显存规划和管理,降低峰值显存和减少显存碎片化;自动对Kernel进行编译优化,提高计算效率;自动接入SOTA的高性能Kernel。
兼容多种硬件
兼容NVIDIA A100/800, H100/800, V100等;兼容阿里云上灵骏集群的硬件资源。
与现有框架对比
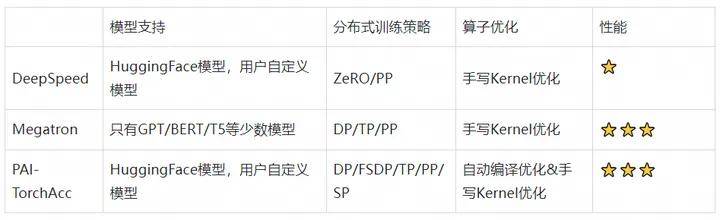
4. PAI-TorchAcc架构
4.1 总体架构
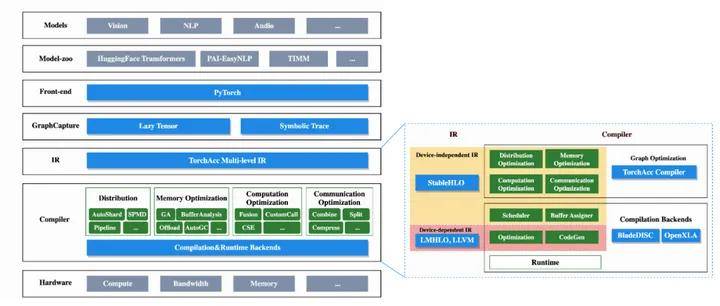
PAI-TorchAcc的架构自顶向下分为以下几层:
模型层:支持计算机视觉、自然语言处理、语音合成等深度学习模型训练的加速;
算法库:支持HuggingFace Transfomers、PAI-EasyNLP、TIMM等算法库构建的模型;
前端:支持以PyTorch为前端语言的模型训练;
Lowering:使用LazyTensor、Symbolic Trace等技术将前端代码转换为静态执行图;
IR:使用多层中间表达,包含High-Level的设备无关的IR和Low-Level的设备相关的IR,基于两层IR上分别做计算图优化和后端编译优化。
编译优化引擎:TorchAcc的编译优化引擎包括计算图优化引擎TorchAcc Compiler和多种后端编译优化引擎BladeDISC和OpenXLA。基于两层IR,进行分布式优化、显存优化、通信优化、计算优化以及算子调度和显存管理等优化,生成优化的设备码。
硬件:最终产生硬件相关的设备码在不同算力、带宽和显存的硬件设备上执行。
4.2 接口
PAI-TorchAcc抽取了一套简洁的接口,灵活接入并加速任意的Pytorch模型,而不需要改动原有的模型代码。
通过 PAI-TorchAcc 加速模型训练一般需要三步:
model = ...
dataloader = ...
+ # 一行代码加速模型,也可传入Config配置更丰富的加速功能,如分布式策略、编译优化选项等
+ model = torchacc.accelerate(model)
+ # 异步加速数据加载
+ dataloader = torchacc.AsyncLoader(dataloader, model.device)
model.train()
for source, labels in dataloader:
4.3 编译优化
PAI-TorchAcc通过LazyTensor、Symbolic Trace等技术将前端Pytorch代码转换为静态执行图,并在静态图上进行自动优化,在分布式的硬件设备上高效运行。
计算图优化
在Tensor Graph上进行优化,这层优化基于High-Level IR——StableHLO进行。
分布式: 通过分图和通信算子插入,完成流水并行、SPMD等。
显存优化:通过算子级别的显存Live range和复用分析、静态调度策略、自动重算、显存管理优化等来减少显存的峰值和碎片化。
计算优化:通过CSE等简化计算,通过算子大粒度融合来优化访存密集型算子,减少kernel launch,减少访存,提升计算效率;通过自动的计算图匹配重写的方式接入Flash Attention等高性能Kernel。
通信优化:通过通信算子的合并、拆分、异步化以及算子的调度来提升通信效率,提高计算和通信的overlap。
后端编译优化
在Buffer Graph上进行优化,这层优化基于Low-Level的IR,包括LHLO、LLVM IR和多种MLIR的dialect。
多后端:支持OpenXLA和阿里自研的BladeDISC两种编译后端;
Lowering和Codegen:将上层的StableHLO Lowering成LHLO和多种MLIR的dialect,并在各级Lowering过程中进行优化,最终表达为LLVM IR,通过LLVM生成针对硬件的优化代码;
Custom Call:High-Level IR自动Pattern rewrite的优化kernel,通过custom call调用。
5. 实践案例和性能
PAI-TorchAcc在A100上能够达到70%的MFU,并且在多卡下几乎线性扩展(8卡到128卡加速比15.6X),在灵活支持各种模型的基础上,性能能够高于Megatron-LM。我们在常见的开源大模型上做了性能测试,使用相同的硬件资源,PAI-TorchAcc的训练吞吐相对PyTorch原生、Megatron均有提升,如LLaMA系列模型相对PyTorch原生提升了140%,相对Megatron提升了5%。
我们将在后续的系列文章中提供一个具体的实践案例:PAI-TorchAcc在OLMo模型训练上的接入示例和加速效果,并且给出加速的来源分析。
6. 总结和未来展望
PAI-TorchAcc可以灵活接入Pytorch模型,并通过并行化策略、显存优化、计算优化和调度优化等方法来加速大模型以及视觉类、语音类模型的训练。PAI-TorchAcc已经在常见大模型上如LLaMA、LLaMA-2、BaiChuan、ChatGLM、QWen、OLMo、Bloom取得了不错的效果。未来我们将从以下方向继续深入优化,以支持更多的场景,取得更好的加速效果。
引用
[1]
[2]
[3]
[4]
[5]
作者:沈雯婷、黄奕桐、艾宝乐、王昂、李永
原文链接:
本文为阿里云原创内容,未经允许不得转载。








评论